
Az informatikai rendszerek és a felhasználók növekedésével a naplózás egyre fontosabbá válik az IT világban, hiszen az alkalmazások optimális teljesítményének és működésének szempontjából elengedhetetlen a naplóállományok vizsgálata és elemzése a hibaelhárítás elvégzéséhez.
Sok esetben azt látjuk, hogy a naplózást már megoldott problémaként kezelik a vállalatok, ugyanis az alkalmazás részeként már nem kell külön fejleszteni, meghatározni a naplóbejegyzések formátumát, hanem elég csak a log keretrendszereket (slf4j, Logrus, stb) paraméterezni. A rendszerek működése során pedig csak ellenőrizni kell a naplófájlokban található bejegyzéseket.
A tapasztalatok mégis azt mutatják, hogy sok esetben ez nem elég. Gondoljunk csak a megviselt arcú kollégáinkra, akik hajnali négykor még különböző szerverekre belépve keresték a hibák okát. A megnövekvő rendszerkomponensek működtetése – microservice és hibridarchitektúrák megjelenésével – egyre nagyobb kihívást jelent főként üzemeltetési szempontból, ezért nélkülözhetetlen a megfelelő eszközök kiválasztása a naplózási gyakorlat kialakításához.
Mi is az a naplózás?
A naplózás a rendszerek, alkalmazások vagy más egyéb komponensek által automatikusan létrehozott és folyamatosan karbantartott rekordokat jelenti, amelyeket az általa elvégzett tevékenységek alapján frissít. Röviden egy alkalmazás leírja magáról, hogy éppen mit csinál, általában időbélyeg és adat (tevékenység) formájában.

Mire jó a naplózás?
A naplóbejegyzések tulajdonképpen nyomkövetésre szolgálnak, amely során végig követhető, hogy a rendszerben vagy a rendszerek között milyen interakciók mentek végbe. Fontos azonban megjegyezni, hogy a naplózás nem csak a problémák felkutatására szolgál, hanem a rendszerek felügyeletére, különböző értesítések (alertek) elvégzésére vagy éppen a rendszerek utilizációjának nyomon követésére.
Kihívások
Vélhetően mindannyian egyetértünk abban, hogy a naplóbejegyzések elemzése kapcsán igencsak komplex feladatokat kell megoldanunk a mindennapi működés biztosítása érdekében. Amennyiben elképzelünk egy architektúrát, amelyben Load Balancer-ek, API Gateway-k, adatbázisok vannak, akkor máris számos kihívásba ütközünk a naplóbejegyzések vizsgálata során. Ha csak a legalapvetőbb és leggyakoribb problémákat emeljük ki, akkor ezek az alábbiak:
- Konzisztencia: Egyik fő probléma a vegyes naplóbejegyzések kezelése, minden alkalmazás vagy eszköz a saját formátuma szerint készíti el a naplóbejegyzéseit. Az egyik bejegyzés például JSON formátumú, míg a másik adatbázis táblába íródik.
- Időbélyeg: Ezáltal különböző időbélyegeket kell tudunk kezelni. Természetesen ezeket belső szabályzással (Governance) valamilyen szinten meg lehet fogni, de ezen meghatározott irányelvek nem feltétlenül alkalmazhatóak a dobozos szoftverek esetén.
- Decentralizáció: Ugyancsak probléma az eltérő helyen keletkező naplóbejegyzések kérdésköre, hiszen számos komponenst rejt magában egy egyszerű architektúra is. így a naplóbejegyzések adatbázisban, szöveges állományokban vagy egyéb formában jöhetnek létre különböző szervereken, táblákban, mappákban.
- Jogosultság: Ha megvannak az naplóbejegyzések, akkor a hasznos adatok kigyűjtése alapvető feladatként jelenik meg. Kinek milyen jogosultsága van? Egy fejlesztő, tesztelő vagy egyéb szerepkörbe tartozó felhasználó milyen bejegyzéseket láthat
- Kompetencia: A kigyűjtött naplóbejegyzések elemzése nem feltétlen triviális feladat, sokszor a komponensek működését is szükséges hozzá ismerni. Így joggal merül fel a kérdés, hogy aki hozzáfér a naplóbejegyzésekhez, tudja is őket értelmezni?
Hogyan tud segíteni az ELK?
Szerencsére manapság számos olyan eszköz létezik, amelyek segítségével kritikus mutatókat és adatokat nyerhetünk ki a naplóbejegyzésekből. Az egyik ilyen eszköz az ELK Stack (Elasticsearch, Logstash és Kibana), amelyről egy rövid bemutatót adunk: Először is nézzük meg magas szinten az előző pontban felvázolt problémákat az ELK Stack szempontjából.
Egy monitoring megvalósítással szemben joggal merül fel az az elvárás, hogy kezelni tudja mind a dinamikus telepítéseket (konténerizáció), mind pedig a régebbi hagyományos infrastruktúrák egyes naplóbejegyzéseit. A naplóbejegyzések központi helyre történő terelése sokkal többet igényel, mint egy egyszerű log keretrendszer konfiguráció. Erre viszont egyszerű megoldást kínál az ELK Stack a struktúrájából adódóan, mivel már kész komponenseket kínál a különböző forráshelyű naplóbejegyzések begyűjtésére. Ennek következtében gyorsan lehet keresni a log rekordok között, hogy megtaláljuk az adott tevékenység kimenetelét. Nincs szükség külön szerverekre SSH-zni az adott hiba felderítése érdekében.
A logok központi elérhetősége azonban még nem hozza meg a kellő áttörést a naplóbejegyzések elemzése kapcsán. Rengeteg az eltérő időbélyeggel vagy különböző struktúrában rögzített adat. Így a következő koncepcionális lépés a strukturált formájú naplóbejegyzésekre történő átalakítás. A naplóbejegyzések strukturálásnak, illetve normalizálásnak hiánya megnehezíti az adatok közötti függőségek feltárását.
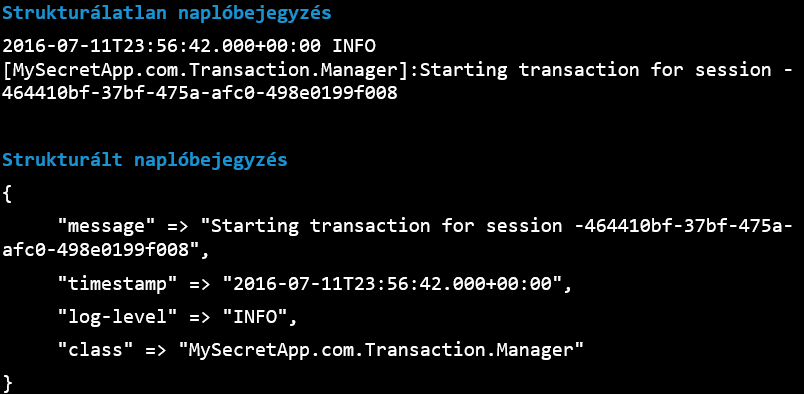
Az ELK Stack a strukturált formára történő alakítás során pattern-ek definiálásával úgynevezett adattisztítási folyamatként is felfogható normalizálást végez. Így a logelemzés során a felbontás mentén egyszerűen és könnyen szűrhetőek lesznek a különböző naplóbejegyzések. Ha egy szemléltető példát kellene mondani, akkor a „log-level” címkére történő kereséssel leszűrhetjük az „INFO” vagy „ERROR” szintű naplóbejegyzéseket. Ezek mellett a pattern-ek további lehetőséget nyújtanak a naplóbejegyzésekhez új mezők hozzáadására, konvertálására, logikai átalakításokra, és egyéb lehetőségekre.
Gondoljunk csak arra, hogy sok esetben a naplóbejegyzésben nincs definiálva a környezet (pl.: dev, int, prod) vagy a különböző alkalmazásokban használt eltérő alias mezőnevekre. Például az egyik rendszerben „correlationId”, míg a másikban már csak „corrId”. Tapasztalataink szerint az előbbi példától sokkal nagyobb eltérések is megjelennek egy szervezeten belül. A naplóbejegyzések konzisztensé tétele egy erős fegyvert ad a kezünkbe a különböző feltételekkel történő szűrésekhez.
A napló adatok centralizálása és strukturálása már önmagában hatalmas könnyítést hoz az üzemeltetők számára, azonban miért is érnénk be ennyivel? A napló tételek elemzését nagyban megkönnyíti az ELK Stack által nyújtott analitikai és vizualizációs platform, amely lehetőséget ad a logbejegyzések összefoglalására, mint például az átlagok, szórások vagy egyéb más metrikák ábrázolására.
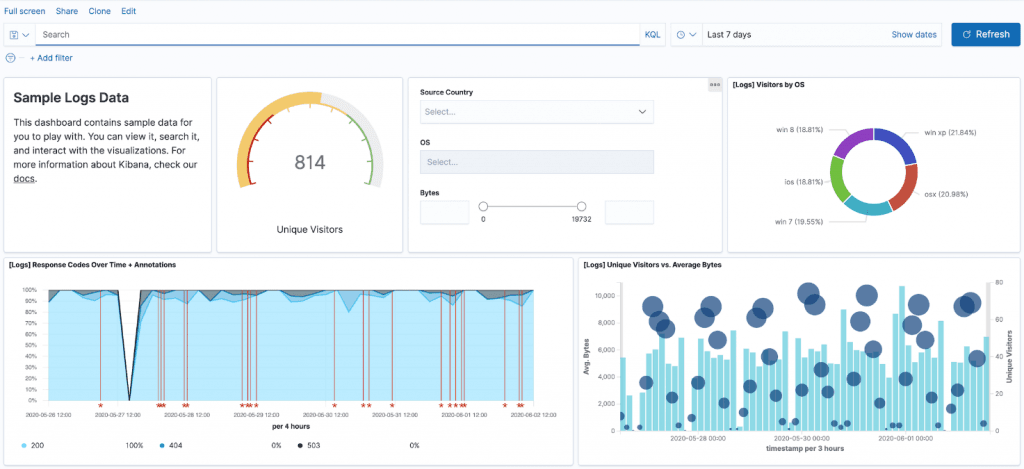
Az adatok vizualizációja, kiértékelése és a hozzájuk tartozó riasztások egy új szintre emelheti az alkalmazások tevékenységeinek ellenőrzését. A különböző grafikonok és az azokhoz tartozó szűrési panelek kialakításával pontosabb betekintés kapható az alkalmazások és szoftverek viselkedésébe, illetve kézenfekvő módon lokalizálhatóak a hibák, anomáliák. A megjelenítendő nézetek optimalizálhatóak oly módon, hogy megfelelő információt hordozzanak a szervezet minden szereplője számára (fejlesztők, üzemeltetők, üzleti elemzők stb.).
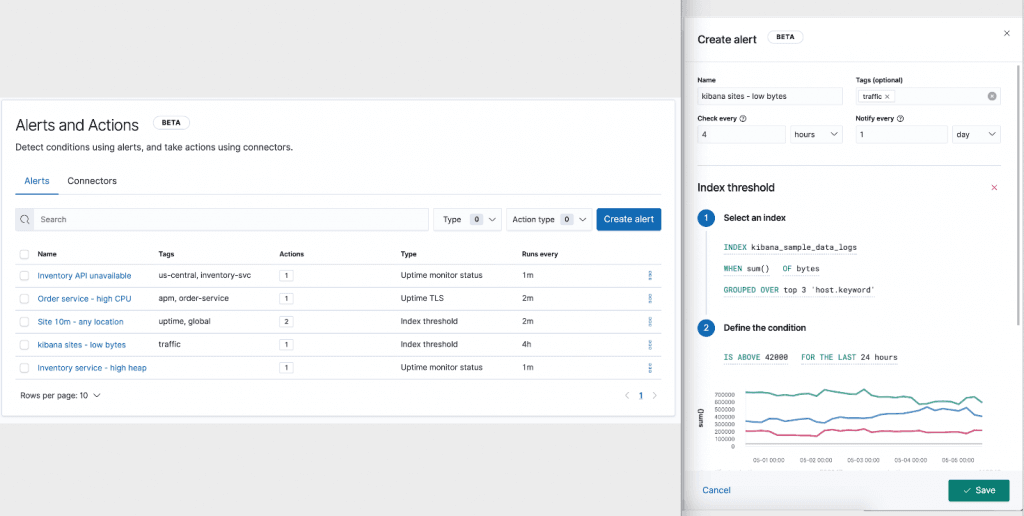
Számos esetben láthatunk nagy kijelzőket az üzemeltető kollégák közelében, ahol színes grafikonok frissülnek másodpercről másodpercre, azonban ezek mit sem érnek, ha nem figyeli őket senki. Így a riasztások definiálása alapvetően a monitorozás egyik alappillérévé vált, hiszen segít felismerni és megválaszolni a rendszer működése során előforduló hibákat, továbbá értesítéseket tud küldeni az illetékeseknek a beavatkozás szükségéről.
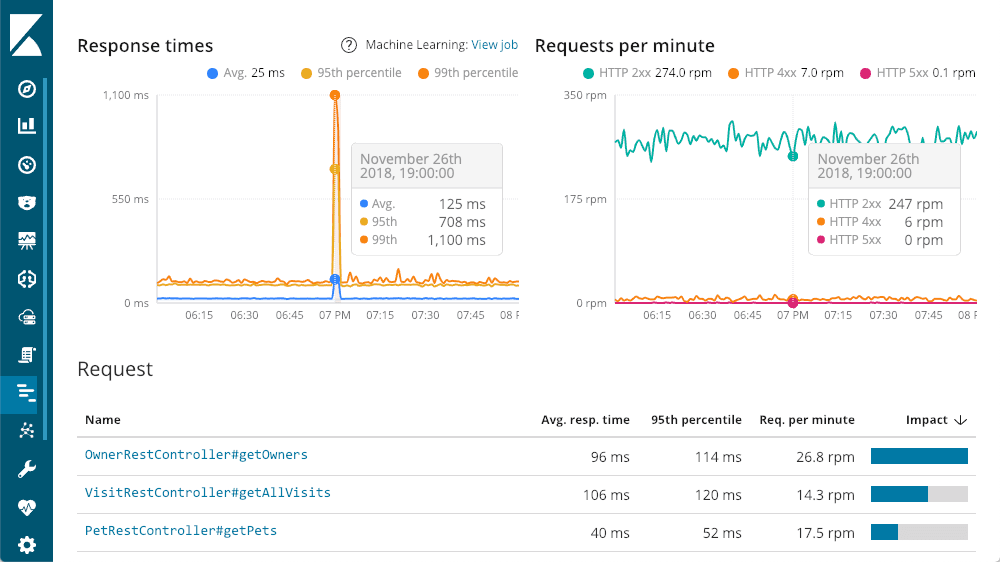
Az ELK Stack számos olyan funkciót biztosít még, amellyel fokozható a naplóbejegyzések elemzése a központi helyre való gyűjtésen, a strukturáláson és a megjelenítésen túl. Egy ilyen eszköz az Application Performance Monitoring (APM), amely áthidalja a naplóbejegyzésekhez és az infrastruktúrához tartozó metrikák közötti réseket, mivel az APM az alkalmazásra összpontosít. Lehetővé teszi például a szolgáltatások és alkalmazások valós időben történő figyelését. Részletes teljesítményinformációk gyűjthetőek a bejövő kérések válasz idejéről, adatbázis lekérdezésekről, nem kezelt hibákról és kivételek detektálásáról.
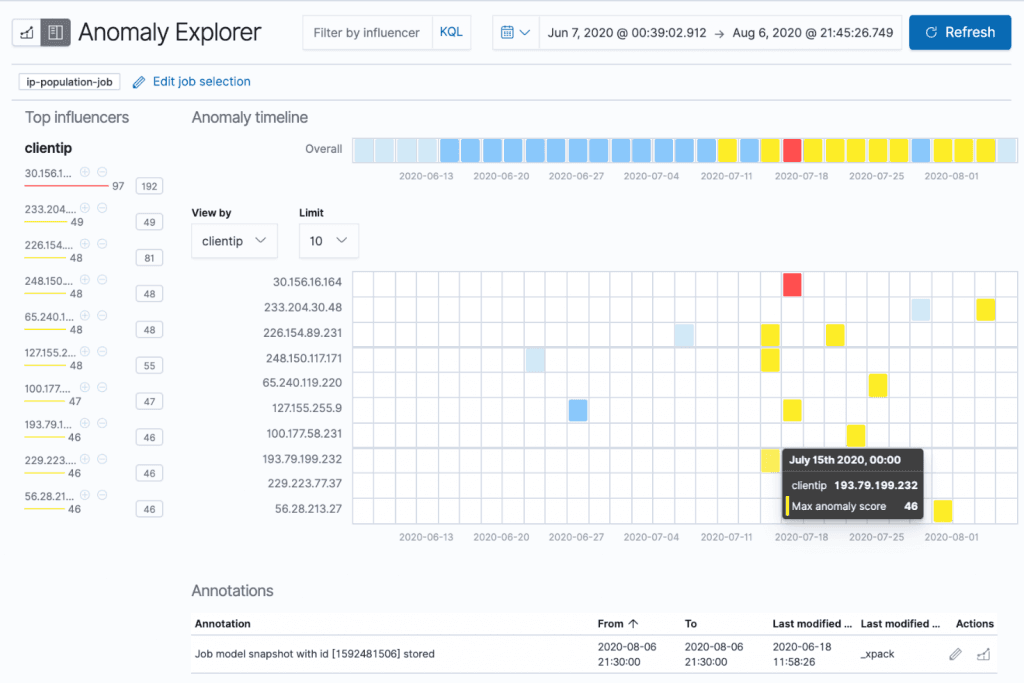
A Machine Learning (későbbiekben ML) funkció bevezetésével tovább finomítható az előforduló anomáliák detektálása, előrejelzések kimutatása vagy éppen a különböző viselkedési normák követése. Az ML segítségével azonosíthatók például a szolgáltatások csúcsidőpontjai, amely alapján skálázást lehet elvégezni az adott alkalmazásokra vonatkozóan. Egy üzleti megoldást említve kiépíthető olyan ML folyamat, ahol előrejelzésre kerülnek a felhasználói viselkedések alapján azon ügyfelek, akik szolgáltatót szeretnének váltani, így potenciálisan megkereshetőek adott esetben kedvezményes ajánlatokkal.
Zárszó
Zárógondoltként hadd jegyezzük meg, hogy az alkalmazások forgalmi szokásaitól, a naplóadatok típusától és az alkalmazás-specifikus követelményektől függően szükséges kiválasztani és konfigurálni a naplóelemző eszközeinket. Azonban a naplóbejegyzésekkel szemben támasztott elemzési, monitorozási igények lefedése esetén érdemes figyelembe venni az ELK Stack által kínált lehetőségeket is.
További információ az ELK-ről a gyártó hivatalos oldalán olvasható.
Pár hasznos cikk mások tollából:
https://logz.io/blog/server-log-analysis/
https://ad-ops.hu/seo/szerver-log-elemzes
https://coralogix.com/log-analytics-blog/logging-best-practices-stages/
https://www.loggly.com/blog/30-best-practices-logging-scale/







